The most comprehensive form of cloud computing services
A futuristic architecture for the insurance industry
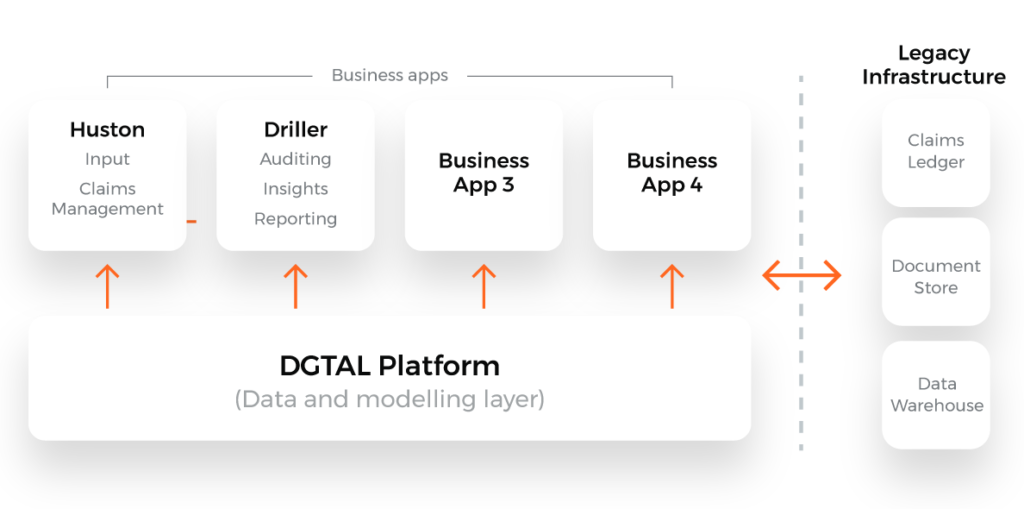
At the core of DGTAL’s architecture is a data and modelling layer (the DGTAL Platform) which is broadly divided into two parts: A stream-oriented data processing pipeline, and a serving layer. The processing pipeline consists of modular components, each performing a specifc task. These processing tasks include, but are not limited to:
Optical character recognition (OCR) on scanned documents.
Indexing of documents and metadata creation
First notification of loss index/ID creation
Data extraction (Policy ID, Name/Address of client or aggrieved party, accident location, vehicle
Named entity recognition.
Document type classification.
Document topic modelling and prediction.
Claims severity regression analysis and prediction.
Matching or enriching data with external knowledge bases.
Each processing stage extracts and enriches the data it receives from the upstream component and provides it to the downstream components, ultimately resulting in enrichment of the claims data with the desired analytical signals while retaining the flexibility of a modular architecture.
The claims data is then projected into the serving layer – a real-time, searchable, aggregations engine – which can be queried independently of the processing layer and serves the different business application that are either provided by DGTAL or are build custom on the top of the platform by the insurer.
DGTAL’s software has interfaces and allows to import as well as export from and to legacy systems such as the existing claims management system or a data warehouse.